
구글(Google)은 정말 공정한가?
구글의 발전 중 중요한 요인이라면 구글이 추구하는 사악해지지 말자라는 말도 압축되는 공정성에 있다고 볼 수 있습니다. 예를 들면, 구글 검색엔진은 페이지 랭크라는 알고리즘으로 웹페이지의 랭킹을 메기며, 구글의 블로그 서비스인 블로거(Blogger)엔 강제적인 광고가 삽입되지 않습니다.
구글 API가 나온 지금에 와서는 구글 내부의 직원(구글러)이나 외부 개발자나 동일한 조건에서 서비스를 만들 수 있는 요건으로 진행되고 있다고 봐도 될 정도입니다. 다른 기업에 비해서 공정하다는 구글도 공정하지 못한 기획이 나오곤 하나 봅니다.
구글은 누가뭐래도 검색의 비중이 매우 높은 기업입니다. 총 매출의 약 1/2을 차지하는 수익을 구글 검색에서 얻고 있으며, 나머지 1/2을 차지하는 애드센스도 검색기술이 바탕이 되고 있습니다. 검색의 공정성을 말할 때 빠지지 않는 것이 robots.txt 파일인데, 이 파일은 자신의 웹페이지들을 검색엔진에 어느 선까지 공개할 것인지를 정하는 것으로 거의 표준으로 정착되어 있는 상태입니다.
구글의 서비스들은 검색엔진의 종류를 불문하고 같은 조건을 걸어놓고 있는데 예외를 팔글에서 찾아냈습니다. 그것은 바로 얼마전 테스트 서비스를 개시한 구글판 플리커(Flickr)인 피카사 웹 앨범(PicasaWeb Album)이라는 서비스입니다.
피카사 웹 앨범의 robots.txt파일을 보면 이렇습니다.
User-agent: Googlebot
Allow: /$
Disallow: /
User-agent: *
Disallow: /
위의 코드를 간단히 설명하자면 User-agent는 검색엔진의 이름을 말합니다. Googlebot은 구글 검색엔진을 말하는 것이고, *는 모든 검색엔진을 말하는 것입니다. 즉, 구글은 /$라는 페이지를 허용하고, 나머지 검색엔진은 허용하지 않는다라는 것인데, /$ 이 페이지는 robots.txt 규약에도 나와있지 않은 매우 생소한 표시입니다.
기술적으로 말하자면 $ 표시는 정규표현식에서 어떤 줄의 마지막을 말합니다. 슬래쉬(/)는 주소의 첫부분을 말하는 것으로, /$ 이것을 풀이하자면, 웹사이트의 첫페이지를 말합니다. 다시 말해서 URL 자체가 됩니다. 페이지로 보면 http://picasaweb.google.com/ 이 페이지입니다.
이런 robots.txt파일 때문에 구글와 야후!, MSN 의 검색엔진 결과를 보면 다음과 같이 나오게 됩니다.
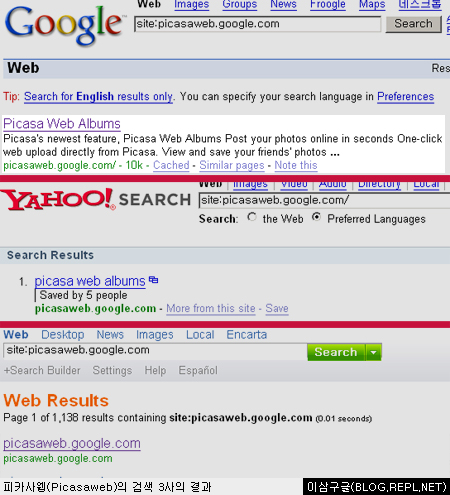
위의 그림을 살펴보면 구글의 경우만 피카사 웹 앨범의 설명이 나오고, 나머지 검색엔진엔 링크만 나오는 것을 알 수 있습니다. 이 이유가 위에서 설명한 robots.txt 때문입니다.
네이버가 진보적인 인터넷 이용자에게 공격 대상이 되는 이유는 네이버에 돈을 내지 않는 웹사이트는 네이버 검색에 나오기가 매우 힘들다는 사실 때문입니다. 네이버의 서비스를 이용하면 네이버 검색에 나오고 그렇지 않으면 나오지 않는다는 것은 공정성 면에서 충분히 공격 받을 만 한 것입니다. 구글은 그런 면에선 깨끗하고 믿을 만 하다는 인식이 퍼져있지만, 이번의 경우 이유가 무엇이건간에 자사의 서비스 정보를 자사 검색엔진에만 제공한다는 것은 비록 테스트 서비스 한페이지 분량이라 하더라도 미래의 공정성에 의심을 갖게 할 충분한 이유가 될 수 있습니다.
아직까지 구글의 행보는 공정성 면에서 타기업에 월등한 모습을 보이고 있습니다. 피카사 웹 서비스의 robots.txt 파일을 이렇게 설정한 것이 개발상 필요에 의해서 불가피한 일이었다고 믿고 싶고, 테스트 딱지를 떼고 나서 이런 일이 발생되지 않기를 바랍니다.
개인적으로는 다른 기업과 마찬가지인 폐쇄적인 서비스를 제공하는 구글의 모습을 보고 싶지는 않습니다.
Comments